The Sixth Puzzle: Partition!
This puzzle proved to be by far the hardest and most complex of the series, unsurprising as it is the final puzzle.
We are greeted with a website with the following text.
Researchers at Stark Industries have developed a new state-of-the-art machine learning model to detect dangerous objects on our planet. These objects may appear harmless on the surface, but could be a significant threat to the Avengers!
The researchers must evaluate the model before the Avengers can begin eliminating identified threats! However, in an underwhelming use of its power, Thanos has used the reality stone to merge the testing and training sets, and the researchers have no idea how to separate them! Can you help them out?.
Below that text is this interface
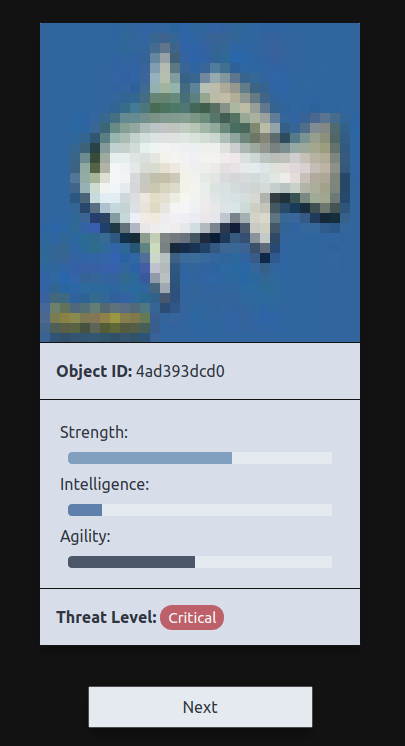
We can see we have an image, and that image has some info, namely strength, intelligence, agility and a threat level.
Below this we have a description of the model architecture of the model.
Machine Learning Model
The identification system uses the model architecture described below, trained on a dataset with a 50-50 training/test split for 15 epochs. The model is optimized using adam with categorical crossentropy loss.
Layer (type) Output Shape Param #
================================================================================
image (InputLayer) (None, 32, 32, 3) 0
conv2d_2 (Conv2D) (None, 32, 32, 64) 1792
conv2d_3 (Conv2D) (None, 30, 30, 64) 36928
max_pooling2d_1 (MaxPooling2D) (None, 15, 15, 64) 0
flatten (Flatten) (None, 14400) 0
dense (Dense) (None, 512) 7373312
dense_1 (Dense) (None, 256) 131328
dense_2 (Dense) (None, 100) 25700
================================================================================
Total params: 7,569,060
Trainable params: 7,569,060
Non-trainable params: 0
At the bottom of the page is a description of our challenge.
Submission
Submit a CSV of 1000 Object IDs contained in the original training set. There is a rate limit of 1 valid submission per 5 minutes. CSVs cannot be larger than 128 KB.
Minimum 85% accuracy required.
Let’s take a step back
That was a lot of information to take in, so let’s summarize. On the HackMIT server there is a machine learning model that is classifying images. This model was trained using one set of images, and tested with another set. These 2 sets have been mixed up.
We can access images and their predicted outputs through this web interface.
Our challenge is to find out which images were used to train the model and which were used to test. We must upload 1000 image IDs, at least 850 of which must be images used in the training set. So we have some leniency, only 85% accuracy is required. We know that the images are 50/50 train and test.
We are told a lot about the architecture of the neural network used to perform the image classification.
How?
This initially seems like an impossible task, how can we possibly know what was used to train the model vs what was used to test.
We could tell which were used to train the model if we knew what the true outputs were for each image, as intuitively the model will be more accurate on the training set.
Our data
We are going to have to download a lot of the images from this interface so let’s take a look at what is happening in the JavaScript to figure out how to automate it.
Looking into the JavaScript we find a lot of interesting information.
Firstly, the outputs shown on the user interface are not the outputs returned from the model, they are actually randomly generated.
The front end is requesting a new image and output from the server, and then displaying random information to the user, strange.
We can see that the actual data returned from the server is a 100-vector of floats, alongside the image.
The key piece of info is a comment that says // update CIFAR-100 image.
CIFAR-100
This comment has told us that the images are actually coming from the CIFAR-100 dataset. This is a public dataset of images divided up into 100 different classes like “vehicle”, “animal”, etc.
So now we know what the 100-vector output from the server really means, it’s a classification vector into the 100 different CIFAR-100 classes. Each entry says how likely the model thinks the image is in each class.
Scraping
Let’s set up a script to scrape lots of images and outputs from the webserver, we are going to need lots of data to beat this puzzle.
At the same time lets download the CIFAR-100 dataset.
Now with our downloaded images from the site we can match them to the real CIFAR-100 set and find out what the true value for the output vector should be.
This means for each image we see on the website we can match it to an image in the CIFAR set and find out what the correct output vector should be, we can then compare this to the vector that the site gives us.
Accuracy
With this info we can calculate roughly how accurate HackMIT’s model really is as a sanity check. We find that the model is about 58% accurate, this tells us that we have been correct so far, If we were comparing the model to random data it would only be about 0.1% accurate.
Back to the problem at hand
Now for each image we know what the true output vector should be, so now can we separate the training set from the test set?
A simple approach would be to pick the top 1000 images that are closest to the real answer.
Unfortunately this doesn’t work out, the server tells us we are between 70 and 85% accurate. This does mean we are on the right track though!
It seems we need a better metric than just the difference between the real data and the prediction data.
Remember at this stage that we haven’t used the model architecture yet. This is a lot of information that we haven’t put to use yet. As we know the model architecture we can train our own version and use it to test our approaches locally.
Generate a local version
Building a matching neural network is a simple task using the Keras python library.
def createMITModel():
# Construct model
mitmdl = Sequential()
mitmdl.add(Conv2D(64, (3, 3), input_shape=(32,32,3), padding='same', activation='relu'))
mitmdl.add(Conv2D(64, (3, 3), activation='relu'))
mitmdl.add(MaxPooling2D(pool_size=(2, 2)))
mitmdl.add(Flatten())
mitmdl.add(Dense(512, activation='relu'))
mitmdl.add(Dense(256, activation='relu'))
mitmdl.add(Dense(100, activation='softmax'))
# compile model
mitmdl.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
return mitmdl
We can feed this with a random 50/50 split of the CIFAR-100 images to make our own local version of the servers model. Crucially however, we know the answer to this local version
More Machine Learning
Deciding whether an image is a test set or a training set image is effectively a binary classification problem. We now have tens of thousands of inputs and outputs for a local version of the same problem. This screams out for machine learning.
We can use our locally generated data to train our own machine learning model to classify training data vs test data.
Our input can be 2 100-vectors, the real data and the prediction data, and the output is just a single number, 0 for training, 1 for test.
We create a simple dense neural network with a 200-vector input and a single output and train it on this new data we generated.
Solved!
When training this network we can see it gets just above 85% accuracy, Perfect!
Let’s take all the images and predictions we’ve downloaded from the puzzle site, match the images to the real CIFAR-100 classification and then run the combined vectors through our model.
If we take the top 1000 images sorted by how sure the model is that they’re test data and submit it to the puzzle site we get our golden ticket. Over 85% accuracy!
That’s it, the last puzzle solved!